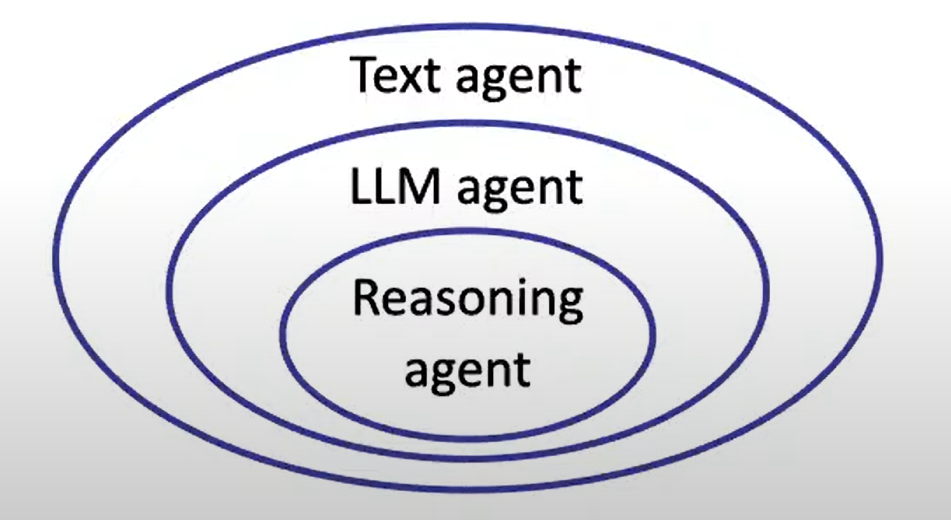
LLM agent 的三个层次
-
Text agent
观察和响应文本
eg. ELIZA、LSTM-DQN
最早的ChatBot

-
LLM agent
仅仅使用LLM做出相应
eg. SayCan、Language Planner
-
Reasoning agent
为LLM加上执行动作和更强的推理能力,Resoning 和 Action
eg. ReAct, AutoGPT
关于Question answering的问题
-
需要推理
Q: 有人说真话,有人说假话,根据他们的话来判断谁说了真话。例如:“A说‘B在撒谎’,B说‘C在撒谎’,C说‘A在撒谎’。其中只有一个人说了真话,谁说了真话?
A: 需要推理
-
需要行动(搜索,计算,编程)
Q: 一个袋子里有5个红球和3个蓝球,随机抽取一个球,抽到红球的概率是多少?
Q: 需要计算
-
需要新知识
Q: 今年英国首相是谁
A: 需要最新资料
推理和行动的手段
sequenceDiagram
participant User
participant Agent
participant Tools
User->>Agent: 提出问题
loop ReAct Process
Agent->>Agent: 推理思考
Agent->>Tools: 执行行动
Tools->>Agent: 返回结果
Agent->>Agent: 分析结果
end
Agent->>User: 返回最终答案
推理 Reasoning
主要是通过思维链(Chain of thoughts)增强可持续时间

行动 Acting
-
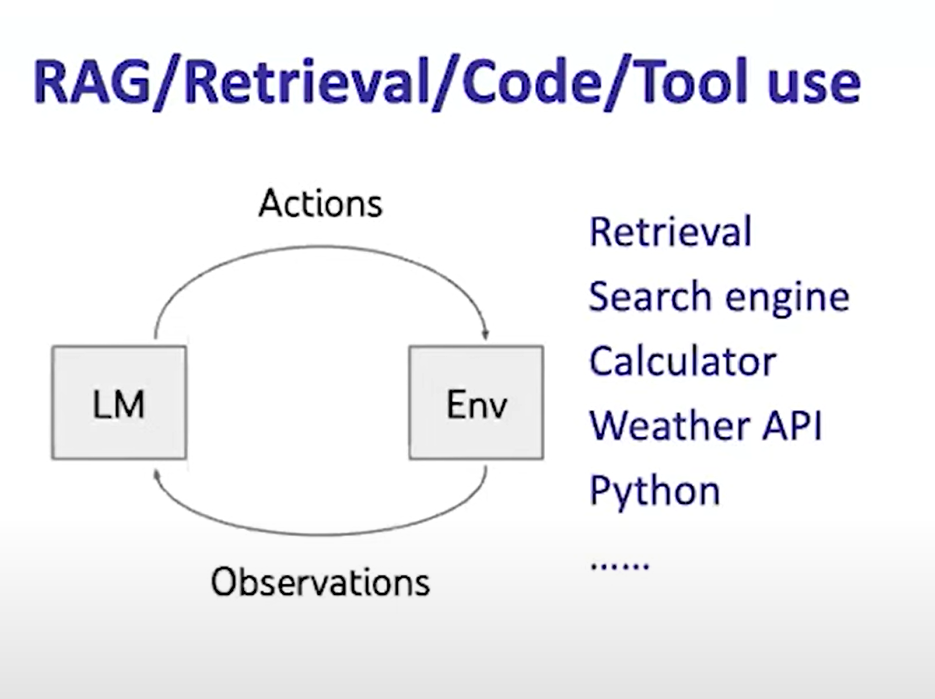
RAG技术
LLM 通过获得额外的最新资料或者retriver来产生新回答
-
Tool Use
- 调用搜索引擎,计算器
- 其它特殊任务模型,例如翻译工具
- API接口,例如查询天气接口等
让Agent的推理和行动协同
只用推理无法获得新信息,只用行动又无法再一次推理
推理可以帮助行动,行动又可以帮助推理,这种思路很像人类解决问题的方法,将两者结合使用可以协同增效
例如 zero-shot ReAct Prompt:
你现在是一个可以使用两种action的代理
- 搜索【关键词】:用谷歌搜索关键词,也可以用它做数学计算
- 结束【回答】:返回回答
你的生成段落应该遵循如下的格式
- 推理思考:观察和分析从搜索行为中得到的信息
- 行动:你可以使用的action
Long-Term memory
llm的记忆一般是很短的,像金鱼一样只有七秒的记忆,如果让llm生成一段程序,但是有错误,那么短期记忆的大模型再修改的过程就无法具备反思的能力,更长的记忆可以让llm的分析和决策能力更强
可以看论文cognitive architectures for language agents(CoALA)
Memory
Action Space
Decision Making
这样的架构可以构建出有很强的创造力的Agent
和human的区别
ReAct agent的思考和行动方式非常像真正的人类行为,但是将其应用到生产活动中还有需要调整的地方
例如人类可能更习惯VSCode这样的交互界面,但是对于digital的agent来说,这样的界面接口可能并不友好
graph LR
A[Interaction Models] --> B[Human Interface]
A --> C[Agent Interface]
B --> B1[Visual IDE]
B --> B2[GUI Tools]
C --> C1[API Calls]
C --> C2[Command Line]
C --> C3[Direct Text]